What is Hashing?
Hashing is a computer science technique for mapping arbitrary-size input to a fixed-size result. A Hash table is a data structure that stores some information, and the information has basically two main components, i.e., key and value. Cryptography, data indexing, data retrieval, and checksum creation are among applications that employ hash functions.
Note:
- Mapping is the way of linking 2 things together, referred to as “Key” and “Value”.
- Key – An Identifier to uniquely identify the Data(Entity).
- Value – The Actual Entity(and its details) which we want to store.
Complexity of Hashing Technique:
The time complexity of hashing is determined by the precise operation being performed, as well as the implementation specifics of the hash table.
- Insertion: O(1) average case, O(n) worst case if there are many collisions and a lot of rehashing is required.
- Deletion: O(1) average case, O(n) worst case if there are many collisions and a lot of rehashing is required.
- Searching: O(1) average case, O(n) worst case if there are many collisions and a lot of rehashing is required.
Basic Operations:
- HashTable: This operation is used in order to create a new hash table.
- Delete: This operation is used in order to delete a particular key-value pair from the hash table.
- Get: This operation is used in order to search a key inside the hash table and return the value that is associated with that key.
- Put: This operation is used in order to insert a new key-value pair inside the hash table.
- DeleteHashTable: This operation is used in order to delete the hash table
| Operation | Description |
| HashTable | This action generates a new hash table by allocating memory for an array of buckets that will hold key-value pairs. |
| Delete | This action deletes a hash table key-value pair. |
| Get | This action obtains from the hash table the value associated with a specific key. |
| Put | Inserts a new key-value pair into the hash table. |
| DeleteHashTable | This action deletes the complete hash table by releasing the memory needed by the bucket array. |
Components of Hashing:
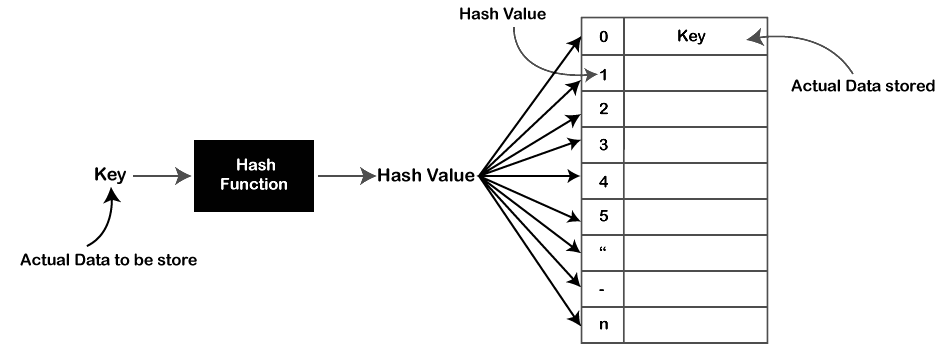
The hash function and the hash table are the two basic components of hashing.
- Hash function: A hash function is a function that accepts a key and returns an integer value known as the hash code or hash value.
- Hash table: A hash table is a fixed-size array that is used to store data. Each array slot is referred to as a bucket, and each bucket can hold one or more key-value pairs.
For instance,
- The key value is “Student1” and the value is the phone number, so when we pass the key value in the hash function shown:
- Hash(key)= index;
- When we pass the key in the hash function, then it gives the index.
- Hash(Student1) = 5;
- The above example adds the john at the index 5.
- When you want to retrieve the phone number associated with the key “Student1”, we would again pass “Student1” through the hash function to get the corresponding index, which in this case is 5.
- Then, we would look in bucket 5 of the hash table to find the associated phone number.
Ways of calculating the Hash function:
- Division Method: It involves dividing the key by the table size and taking the remainder as the hash code. The formula for this method is:
- hash(key) = key % table_size.
- Multiplication Method: It involves multiplying the key by a constant value between 0 and 1, and then taking the fractional part of the product as the hash code. The formula for this method is:
- hash(key) = floor(table_size * ((key * constant) % 1)).
- Folding Method: This involves dividing the key into equal-sized chunks (of some number of digits), adding the chunks together, and then taking the remainder of this sum as the hash code. The formula for this method is:
- hash(key) = (chunk1 + chunk2 + … + chunkn) % table_size.
Collision Handling:
Because a hash function returns a tiny number for a large key, it is possible that two keys will return the same value. A collision occurs when a newly added key maps to an existing occupied space in a hash table and must be handled using a collision handling strategy. The following are some methods for dealing with collisions:
- Separate Chaining: In this method, each hash table bucket is a linked list. When a key-value pair collides, it is simply added to the linked list for that bucket.
- Open Addressing: When a collision occurs, the hash table searches for the next open position in the array, beginning with the original index. This may be accomplished by a variety of approaches, including linear probing (in which the hash table tests the next index in the array) and quadratic probing (in which the hash table checks the next index using a quadratic function).
Example:
For instance, we have a hash table of size 5, and we want to store the following key-value pairs:
- “apple”: 3
- “banana”: 7
- “cherry”: 12
- “dog”: 2
To store these values in the hash table, we’ll use the division method to calculate a hash code for each key. However, the keys “cherry” and “dog” both have the same hash code of 2, i.e., both will be stored at index 2 in the table which is a collision and needs to be handled.
Using chaining, where each table entry is a linked list of key-value pairs that have the same hash code we can store the key-value pairs:
index 2: ("cherry", 12) -> ("dog", 2)
index 3: ("apple", 3)
index 4: ("banana", 7)Now we have a linked list at index 2, which contains the key-value pairs for both “cherry” and “dog”.
To retrieve a value from the hash table, first calculate the hash code for the key, and then traverse the linked list at the corresponding index until we find the key we’re looking for.
For example, to retrieve the value for the key “cherry”, we calculate the hash code as hash(“cherry”) = 2, and then traverse the linked list at index 2 until we find the key “cherry”, whose value is 12.
Problem-based on Hashing:
Given a binary string s without leading zeros, return true if s contains at most one contiguous segment of ones. Otherwise, return false.
Example 1:
Input: s = "1001" Output: false Explanation: The ones do not form a contiguous segment.
Example 2:
Input: s = "110" Output: true
Solution:
class Solution {
public boolean checkOnesSegment(String s) {
Set<Integer> onesIndices = new HashSet<>();
for (int i = 0; i < s.length(); i++) {
if (s.charAt(i) == '1') {
onesIndices.add(i);
}
}
if (onesIndices.size() <= 1) {
return true;
}
int minIndex = Integer.MAX_VALUE;
int maxIndex = Integer.MIN_VALUE;
for (int index : onesIndices) {
minIndex = Math.min(minIndex, index);
maxIndex = Math.max(maxIndex, index);
}
return maxIndex - minIndex + 1 == onesIndices.size();
}
}Time complexity: O(n), where n is the length of the input string
Space complexity: O(n), where n is the length of the input string
In this implementation, we use a HashSet named onesIndices to store the indices of the ones in the binary string s. We iterate through the characters of s and whenever we encounter a ‘1’, we add its index to the onesIndices set.
Next, we check if the size of the onesIndices set is less than or equal to 1. If so, it means there is at most one contiguous segment of ones in the string, and we return true.
Note: also read about DSA: Collision in Hashing
Follow Me
If you like my post please follow me to read my latest post on programming and technology.
Leave a Reply
You must be logged in to post a comment.