Introduction to Mule 4: Error Handlers
To handle better error mechanisms in Mule 4, here we discuss how Mule 4 comes with an integrated and effective error handling approach.
What is Error Handling
An exception occurs when an unexpected event happens while processing. Exception (or error) handling is the process of responding to exceptions when a computer program runs.
In Mule 4, error handling is no longer limited to a Java exception handling process that requires you to check the source code or force an error in order to understand what happened. Though Java Throwable errors and exceptions are still available, Mule 4 introduces a formal Error concept that’s easier to use. Now, each component declares the type of errors it can throw, so you can identify potential errors at design time.
Mule Errors
Execution failures are represented with Mule errors that have the following components:
- Error description – will always be string. Syntax: error.description
- Error type – Exemplifies problem. Namespace and identifier indicate the type of error. Each error type has a parent and by default, ANY is the parent type for any error. Syntax: error.errorType
- Error cause – Indicates the cause that triggered the execution failure. Syntax: error.cause
- Error message – Communicates and makes the error message more clear. Syntax: error.message
We can go back to the flow and click the listener responses and we can see the error.description part.
In Mule, we can handle the message exception at different levels.
- At project level using the Default error handler.
- At project level using the Custom Global error handler.
- At flow level in exception handling using the Raise Error component, On-Error Continue and On-Error Propagate.
- At flow or at processor level using the Try scope.
Whenever an error occurs in a flow, an error object is created. It contains many properties, like error.description or error.errorType.
The errorType property is a combination of Namespace and Identifier. For example, HTTP:UNAUTHORIZED, where the Namespace is HTTP and the Identifier is UNAUTHORIZED.
Mule identifies the error based on the errorType and then routes it to its respective block that is placed inside the Error Handler.
Whenever an error occurs the natural Mule execution flow halts and an event is raised and passed to the error handler. The error handler component can contain any number of internal handler scopes defined within it. Each internal error handler scope can have many event processors. On-error-continue and on-error-propagate are the internal error handlers. As the event is passed to each error handler, the appropriate internal error handler is identified and directed to it. The detailed flow of user-defined error handler is illustrated in the below figure:
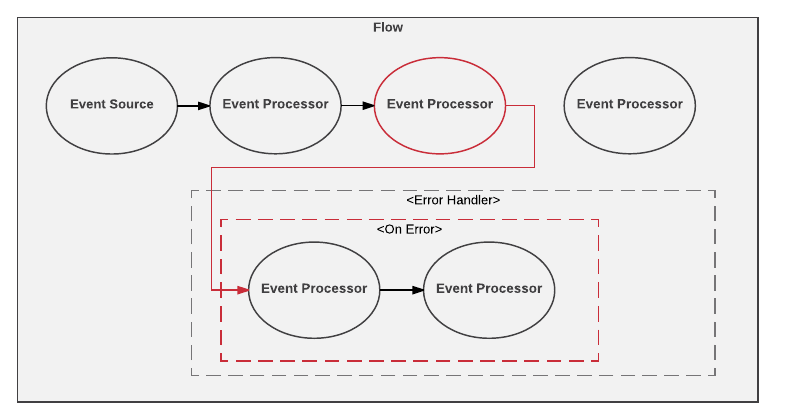
Figure: User Defined Error Handling flow
Scope: In error handling there are two scopes.
- On Error Propagate
- On Error Continue

Figure: Flow of on Error Continue and On Error Propagate Scope
Coming to the flow now in which we will drag and drop the on error propagate scope and in the scope will add a set payload giving a message.
Now redeploy the application.
We will get a response like this i.e, 500 Server Error when we will give the request without giving any queryParams.
In On Error Propagate it works like a Rollback function i.e, even when the error is thrown it does some action and terminates the entire flow and then throws the entire error to its parent flow it means that it handles the error but it does not kill the error.
Now instead of On Error Propagate we will put On Error Continue in the flow and give a set payload there giving a message.
Again redeploy the application and send the same request.Here we can see that in On Error Continue it is not throwing the error to the parent flow it’s giving an 200 OK response.From here we can make the difference between both error scope i.e, in On Error Propagate it is giving 500 Server Error and also it is giving the message given in the validator but in On Error Continue it is giving 200 OK Response and giving the message given in the set Payload of the error Scope.
Default Error Handling
If the error handler is undefined, inherently the default Mule 4 error handler takes care of error handling, offering no configurability options. To increase the visibility of the error it is suggested to define the error handling block.

Figure: Default Error Handling Flow
Try Scope
For the most part, Mule 3 only allows error handling at the flow level, forcing you to extract logic to a flow in order to address errors. In Mule 4, we’ve introduced a Try scope that you can use within a flow to do error handling of just inner components. The scope also supports transactions, which replaces the old Transactional scope.
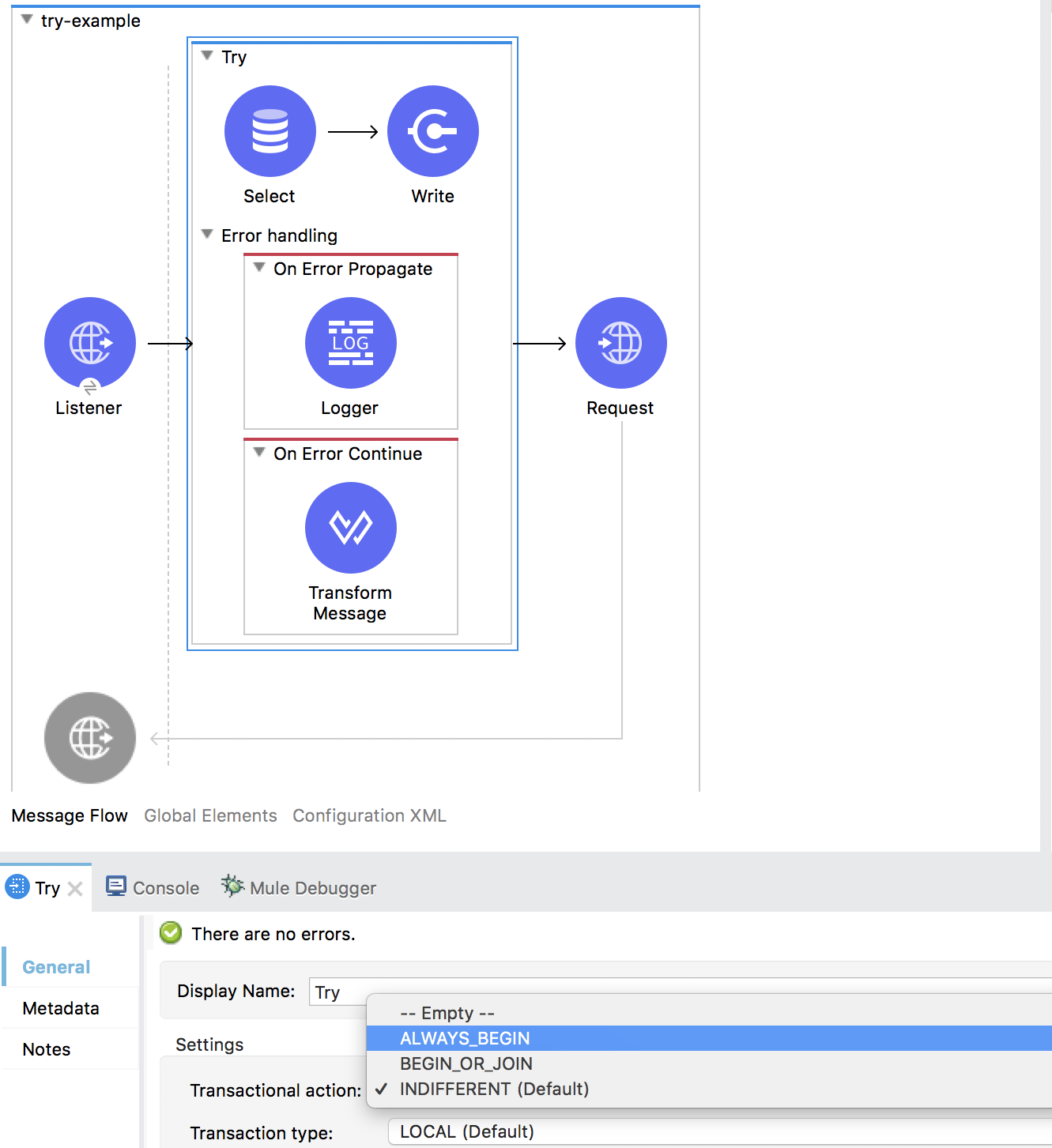
The error handler behaves as we have explained earlier. In the example above, any database connection errors are propagated, causing the try to fail and the flow’s error handler to execute. In this case, any other errors are handled, and the Try scope is considered successful which, in turn, means that the next processor in the flow, an HTTP request, continues its execution.
Error Mapping
Mule 4 now also allows for mapping default errors to custom ones. The Try scope is useful, but if you have several equal components and want to distinguish the errors of each one, using a Try on them can clutter your app. Instead, you can add error mappings to each component, meaning that all or certain kinds of errors streaming from the component are mapped to another error of your choosing. If, for example, you are aggregating results from 2 APIs using an HTTP request component for each, you might want to distinguish between the errors of API 1 and API 2, since by default, their errors are the same.
By mapping errors from the first request to a custom API_1 error and errors in the second request to API_2, you can route those errors to different handlers. The next example maps HTTP:INTERNAL_SERVER_ERROR so that different handling policies can be applied if the APIs go down (propagating the error in the first API and handling it in the second API).
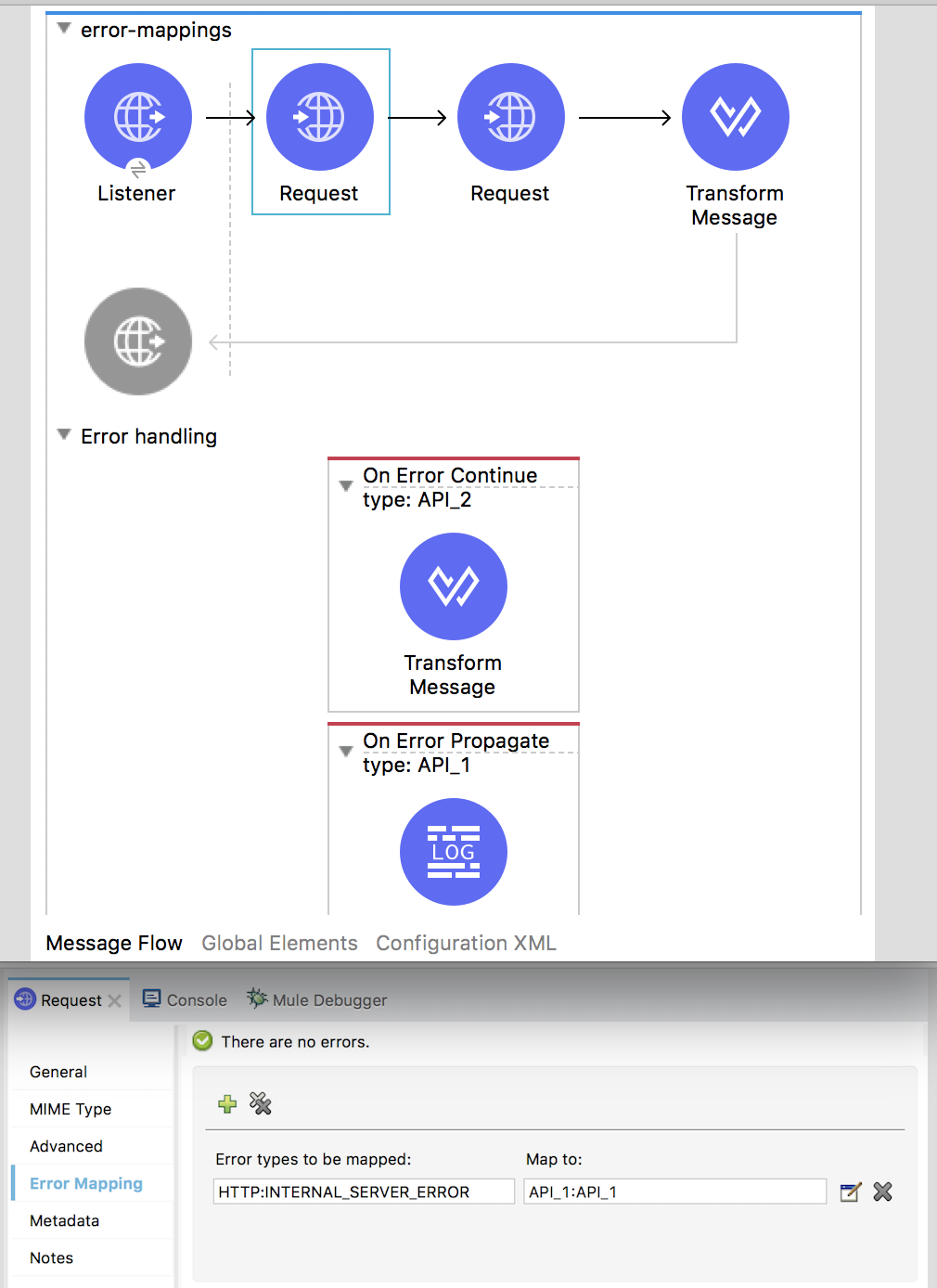
The difference between a flow, a sub-flow and a private flow, is that sub-flow doesn’t have an Error Handling scope. So, it’s just flow and private flow, the ones that have an Error Handling block and can contain the On-Error Propagate and On-Error Continue.
Whether it is Propagate or Continue, Mule Executes all the components within those blocks.
Remember: The error will route to the Error Handling only if it identifies that the error-type from the error matches with what you have set in your Error Handling block.
Mule 4 has one excellent feature that can identify the types of errors that can occur within that flow by looking at what kind of connectors are placed in that particular flow since we have an HTTP Request and Database components, the drop-down shows all the types of errors that can happen in different scenarios from these two components. It even shows the EXPRESSION error type (not in the picture) because there are some DataWeave syntax’s in the flow.
It will be very easy to learn Error Handling by knowing how On-Error Propagate and On-Error Continue work. We shall follow some set of rules to identify the flow of process. That way we can determine what is the result payload status-code.
Rules
Before learning about rules. We must not forget that a RAML-based generated HTTP Listener will have the Error Response Body set as “payload” by default, but a manually drag-and-drop HTTP Listener will have output text/plain – – – error.description set by default. So, remember to change this according to your business requirements.
Here are the rules to remember when an error has occurred in any flow:
Rule 1:
- If anything is present in the Error Handling section. Even if there are On-Error Propagate and On-Error Continue blocks, make sure that your particular error-type is handled by those.
- If not, then Mule will use the default Error Handling. If your flow is not called by any other flow, then it will display the default value that is set in the Error Response Body and will return a status code of 500 by default, if nothing is manually set. If your flow is called by any other flow, then the error will be raised to the calling flow.
Rule 2: If Error Handling is present in that particular flow and error-type is handled (Rule 1.1), then check whether it is On-Error Continue or On-Error Propagate. In both the cases, Mule will execute all components within that block.
Rule 3: After the execution of all the components, now:
- If the error is handled using On-Error Propagate, it will raise an error back to the calling flow.
- If the error is handled using On-Error Continue, it will not raise an error back to the calling flow and continue to the next processor after “flow-ref” and continues further process as it is. But it will not continue to other processors in the flow where the error is handled.
- Suppose you have only a single flow. Then On-Error Propagate and On-Error Continue behave the same way, except that On-Error Continue gives 200 status and On-Error Propagate gives 500 status. Because, as explained, even if it’s On-Error Continue, it will not go to the next processor within the same flow.
- Always remember, this point is very important. On-Error Continue will continue only to the next processor of the calling flow but it will not continue within the same flow.
Follow Me
If you like my post please follow me to read my latest post on programming and technology.
Leave a Reply
You must be logged in to post a comment.