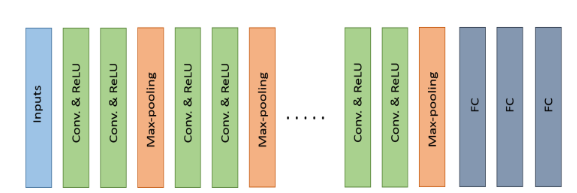
There are several popular state-of-the-art CNN architectures. In general, most deep convolutional neural networks are made of a key set of basic layers, including the convolution layer, the sub-sampling layer, dense layers, and the soft-max layer.🤗🤗
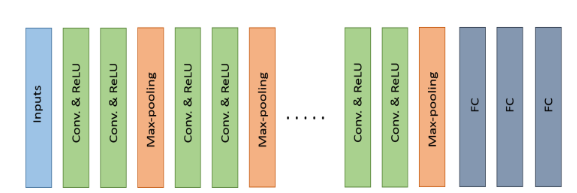
The architectures typically consist of stacks of several convolutional layers and max-pooling layers followed by a fully connected and SoftMax layers at the end.
Some examples of such models are LeNet, AlexNet, VGG Net, NiN, and all convolutional (All Conv). Other alternatives and more efficient advanced architectures have been proposed including GoogLeNet with Inception units, Residual Networks, DenseNet, and FractalNet. 😝😝
The basic building components (convolution and pooling) are almost the same across these architectures. However, some topological differences are observed in the modern deep learning architectures.
Of the many DCNN architectures, AlexNet, VGG, GoogLeNet, Dense CNN, and FractalNet have generally considered the most popular architectures because of their state-of-the-art performance on different benchmarks for object recognition tasks.
Among all of these structures, some of the architectures are designed especially for large scale data analysis (such as GoogLeNet and ResNet), whereas the VGG network is considered a general architecture.
Some of the architectures are dense in terms of connectivity, such DenseNet. Fractal Network is an alternative of ResNet.
LeNet (1998) 😝👇
Although LeNet was proposed in the 1990s, limited computation capability and memory capacity made the algorithm difficult to implement until about 2010.
LeCun, however, proposed CNNs with the back-propagation algorithm and experimented on handwritten digits dataset to achieve state-of-the-art accuracies.
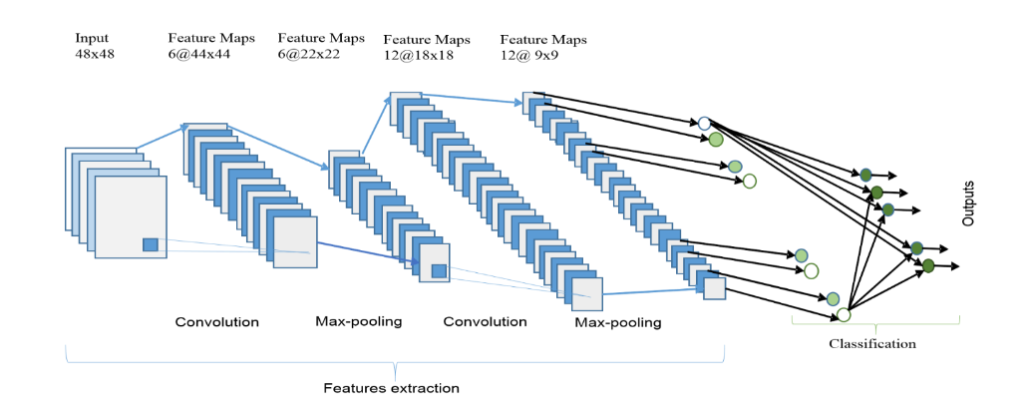
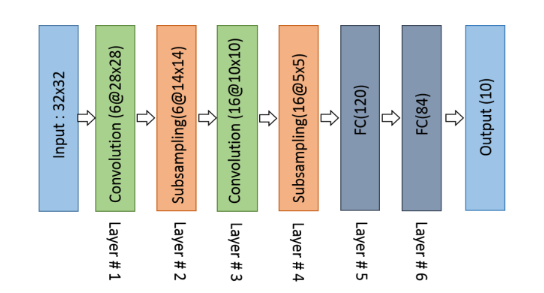
His architecture is well known as LeNet-5. The basic configuration of LeNet-5 is (see Fig. 2):2 convolution (conv) layers, 2 sub-sampling layers,2 fully connected layers, and an output layer with Gaussian connection.
The total number of weights and Multiply and Accumulates (MACs) are 431k and 2.3M respectively.
AlexNet (2012) 😲👇
In 2012, Alex Krizhevesky and others proposed a deeper and wider CNN model compared to LeNet and won the most difficult ImageNet challenge for visual object recognition called the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012.
AlexNet achieved state-of-the-art recognition accuracy against all the traditional machine learning and computer vision approaches.
The architecture of AlexNet is shown in Fig.3. The first convolutional layer performs convolution and maxpooling with Local Response Normalization (LRN) where 96 different receptive filters are used that are 11×11 in size.
The max pooling operations are performed with 3×3 filterswith a stride size of 2. The same operations are performed in the second layer with 5×5 filters.
3×3 filters are used in the third, fourth, and fifth convolutional layers with 384, 384, and 296 feature maps respectively.
Two fully connected (FC) layers are used with dropout followed by a Softmax layer at the end. Two networks with similar structure and the same number of feature maps are trained in parallel for this model.
AlexNethas3 convolutionlayersand2 fully connected layers. When processing the ImageNet dataset. The total number of weights and MACs for the whole network are 61M and 724M respectively.
ZFNet / Clarifai (2013) 🤗👇
In 2013, Matthew Zeiler and Rob Fergue won the 2013 ILSVRC with a CNN architecture which was an extension of AlexNet. The network was called ZFNet, after the authors’ names.
The ZFNet architecture is an improvement of AlexNet, designed by tweaking the network parameters of the latter. ZFNet uses 7×7 kernels instead of 11×11 kernels to significantly reduce the number of weights. This reduces the number of network parameters dramatically and improves overall recognition accuracy.
Network in Network (NiN) 😵👇
his model is slightly different from the previous models where a couple of new concepts are introduced [60]. The first concept is to use multilayer perception convolution, where convolutions are performed with a 1×1 filters that help to add more non linearity in the models.
This helps to increase the depth of the network, which can then be regularized with dropout. This concept is used often in the bottleneck layer of a deep learning model.
The second concept is to use the Global Average Pooling (GAP) as an alternative to fully connected layers. This helps to reduce the number of network parameters significantly.
GAP changes the network structure significantly. By applying GAP on a large feature map, we can generate a final low dimensional feature vector without reducing the dimension of the feature maps.
VGGNET (2014) 😍👌👇
The Visual Geometry Group (VGG), was the runner up of the 2014 ILSVRC.
The VGG architecture consists of two convolutional layers both of which use the ReLU activation function. Following the activation function is a single max pooling layer and several fully connected layers also using a ReLU activation function.
The final layer of the model is a Softmax layer for classification. In VGG-E the convolution filter size is changed to a 3×3 filter with a stride of 2.
Three VGG-E models, VGG-11, VGG-16, and VGG-19; were proposed the models had 11,16, and 19 layers respectively. All versions of the VGG-E models ended the same with three fully connected layers.
However, the number of convolution layers varied VGG-11 contained 8 convolution layers, VGG-16 had 13 convolution layers, and VGG-19 had 16 convolution layers. VGG-19, the most computational expensive model, contained 138M weights and had 15.5M MACs.
GoogLeNet (2014) 😗😘👇


GoogLeNet, the winner of ILSVRC 2014, was a model proposed by Christian Szegedy of Google with the objective of reducing computation complexity compared to the traditional CNN.
He proposed method was to incorporate “Inception Layers”that had variable receptive fields, which were created by different kernel sizes. These receptive fields created operations that captured sparse correlation patterns in the new feature map stack.
The initial concept of the Inception layer can be seen in Fig. 6 (Right). GoogLeNet improved the state of the art recognition accuracy using a stack of Inception layers seen in Fig. 6 (Left).
The difference between the naïve inception layer and final Inception Layer was the addition of 1×1 convolution kernels. These kernels allowed for dimensionality reduction before computationally expensive layers.
GoogLeNet consisted of 22 layers in total, which was far greater than any network before it. However, the number of network parameters GoogLeNet used wasmuch lower than its predecessor AlexNet or VGG.
GoogLeNet had 7M network parameters when AlexNet had 60Mand VGG-19 138M. The computations for GoogLeNet also were 1.53G MACs far lower than that of AlexNet or VGG.
Residual Network (ResNet in 2015) 😗✌️👇


The winner of ILSVRC 2015 was the Residual Network architecture, ResNet. ResNet was developed by Kaiming He with the intent of designing ultra-deep networks that did not suffer from the vanishing gradient problem that predecessors had.
ResNet is developed with many different numbers of layers; 34, 50,101, 152, and even 1202.
The popular ResNet50 contained 49 convolution layers and 1 fully connected layer at the end of the network.
The total number of weights and MACs for the whole network are 25.5M and 3.9M respectively.
The residual network consists of several basic residual blocks. However, the operations in the residual block can be varied depending on the different architecture of residual networks. The wider version of the residual network was proposed by Zagoruvko el at. In 2016.
Another improved residual network approach known as the aggregated residual transformation was proposed in 2016. Recently, some other variants of residual models have been proposed based on the Residual Network architecture[68, 69, and 70].
Furthermore, there are several advanced architectures that have been proposed with the combination of Inception and Residual units.
Densely Connected Network (DenseNet in 2017) 🤔👇
DenseNet developed by Gao Huang and others in 2017, which consists of densely connected CNN layers, the outputs of each layer are connected with all successor layers in a dense block. Therefore, it is formed with dense connectivity between the layers rewarding it the name “DenseNet”.
This concept is efficient for feature reuse, which dramatically reduces network parameters. DenseNet consists of several dense blocks and transition blocks, which are placed between two adjacent dense blocks. The conceptual diagram of a dense block is shown in Fig.5.
FractalNet (2016) 😜👇

This architecture is an advanced and alternative architecture of ResNet model, which is efficient for designing large models with nominal depth, but shorter paths for the propagation of gradient during training.
This concept is based on drop-path which is another regularization approach for making large networks. As a result, this concept helps to enforce speed versus accuracy trade-offs. The basic block diagram of FractalNet is shown in Fig.21.
Capsule (CapsNet) 🤔🤔
he capsule network consists of several layers of capsule nodes. The first version of capsule network (CapsNet) consisted of three layers of capsule nodes in an encoding unit.
Reference: The History Began from AlexNet: A Comprehensive Survey on Deep Learning Approaches
Follow Me ❤😊
If you like my post please follow me to read my latest post on programming and technology.
Leave a Reply
You must be logged in to post a comment.